Parallelizing Derivative Solves of Multipoint Models At a Small Memory Cost#
A fan-out structure in a model is when you have a data path through the model that starts out serial and then reaches a point where multiple components can be run in parallel. This model structure is common in engineering problems, particularly in multi-point problems where you want to evaluate the performance of a given system at multiple operating conditions during a single analysis.
For example, consider a simple example problem as follows:
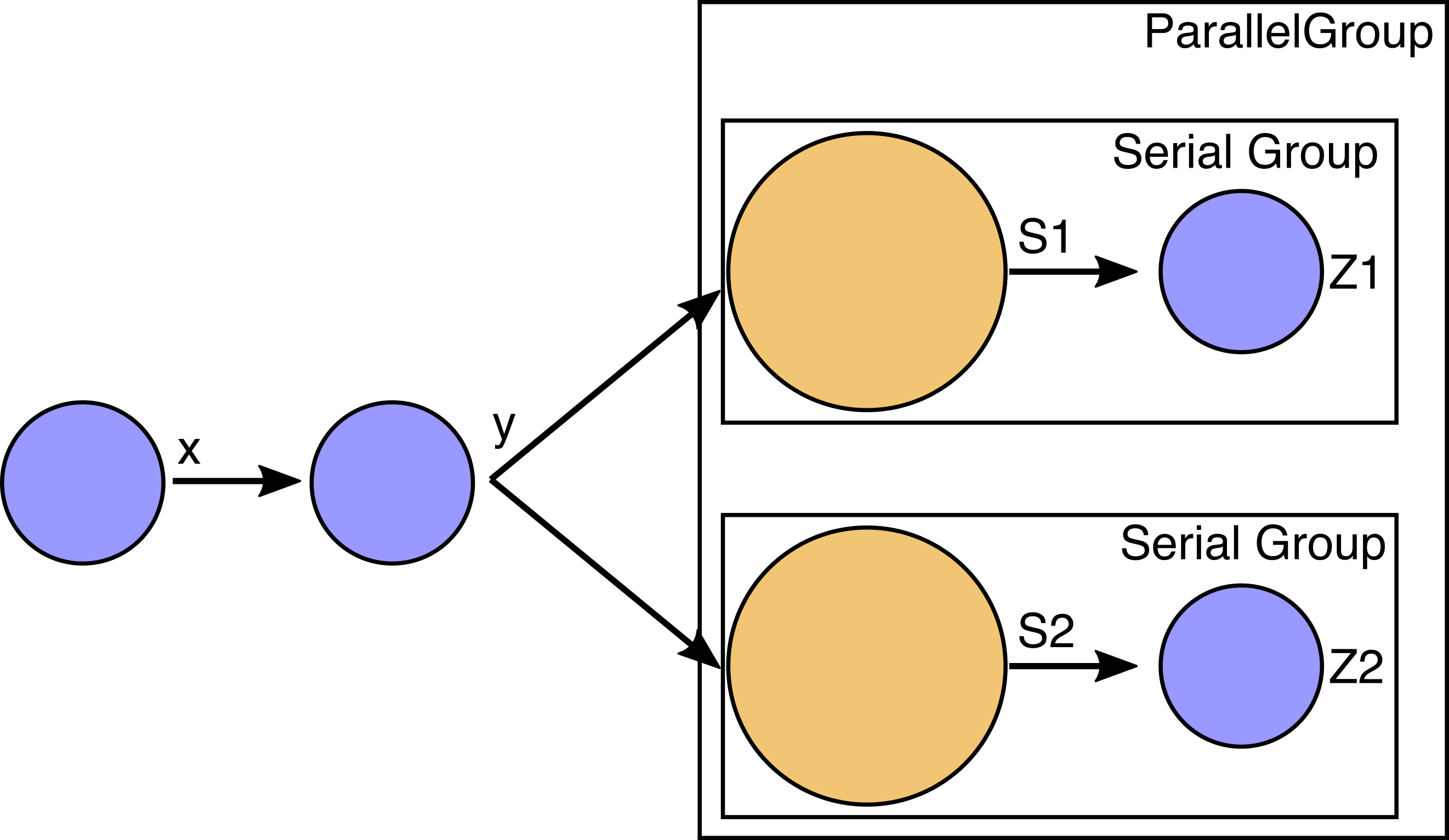
Assume that the variables x and y are size 100 array variables computed by inexpensive components.
These are upstream of the expensive implicit analyses (e.g. some kind of PDE solver) computing the very large
implicit variables s1 and s2 (noted in yellow similar to the coloring in an N2 diagram).
Lastly there are two scalar variables z1 and z2, computed using the converged values for s1 and s2.
The components that compute s1,z1 and s2,z2 have no dependence on each other so we put them into a parallel group and each group can run on its own processor (or set of processors). The upstream components that compute x and y are a serial bottleneck, but they are very inexpensive compared to the expensive components in the parallel group. So we can expect to get reasonable parallel scaling when running the nonlinear analysis a model set up like this.
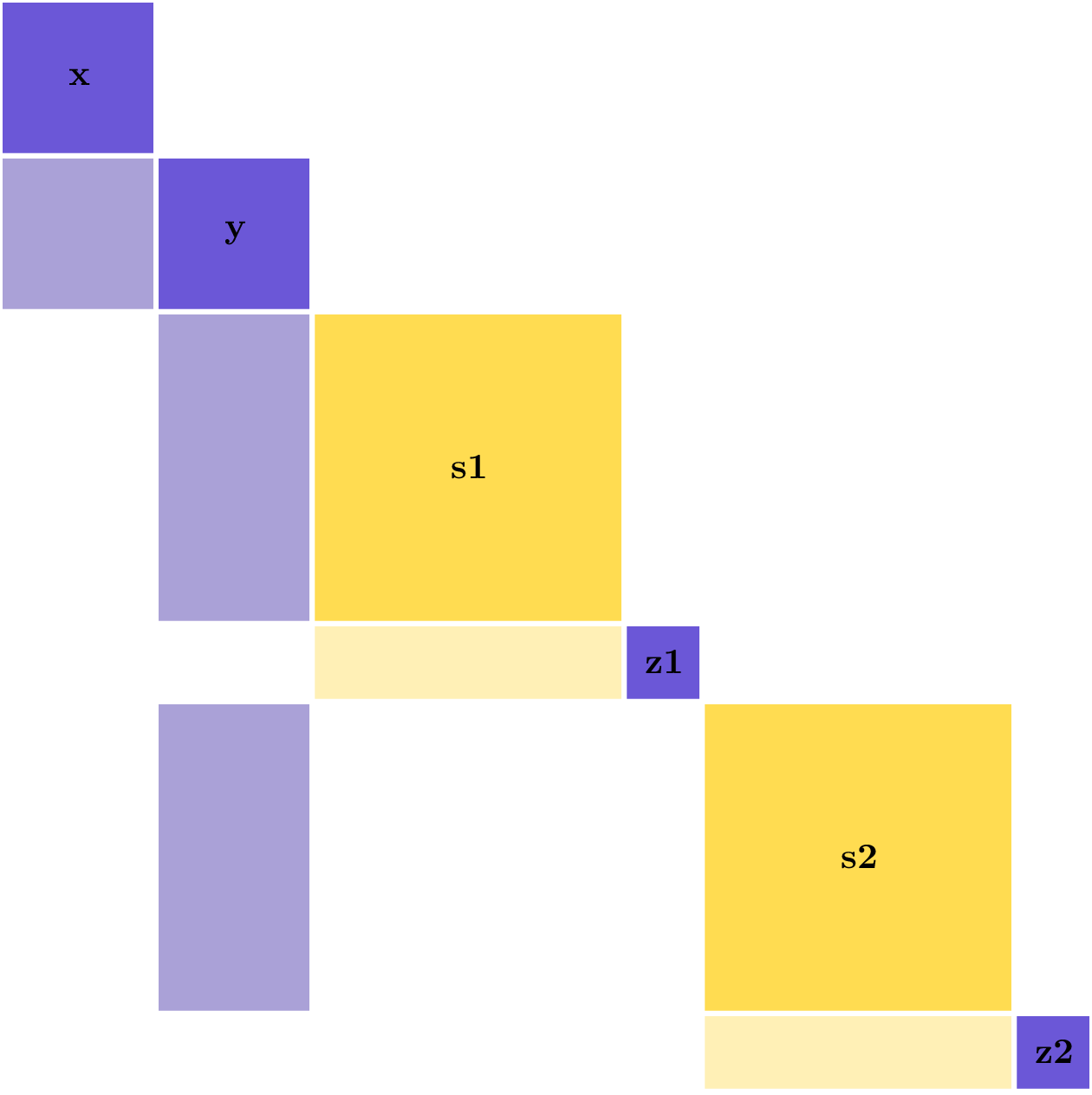
This potential for parallelization can also be seen by looking at the partial-derivative Jacobian structure of this example model.
The dense column for y means that you must compute it before you can compute s1,z1 and s2,z2.
However, the block-diagonal structure for s1,z1 and s2,z2 means that these parts of the model can be run in parallel.
If we want to compute the derivatives \(\frac{dz1}{dx}\) and \(\frac{dz2}{dx}\), then reverse mode is preferred because it requires 2 linear solves instead of 100, but there is an inherent inefficiency that will limit the parallel scalability of reverse mode that needs to be considered as well.
Given the feed-forward structure of this model, the LinearRunOnce solver is recommended, which will use a back-substitution-style algorithm to solve for total derivatives in reverse mode.
Looking at the linear system needed to solve in reverse mode, we see that the dense column for y in the partial derivative Jacobian has now become a dense row —in reverse mode you use \(\left[ \frac{\partial R}{\partial U} \right]^T\) — and because we’re using back-propagation, that dense row now occurs after the two parallel constraints in the execution order (remember that order is reversed from the forward pass).
You can see that in each of the two solution vectors, the entries for y and x are highlighted as nonzero, and hence they would overlap if you tried to perform both linear solves at the same time.
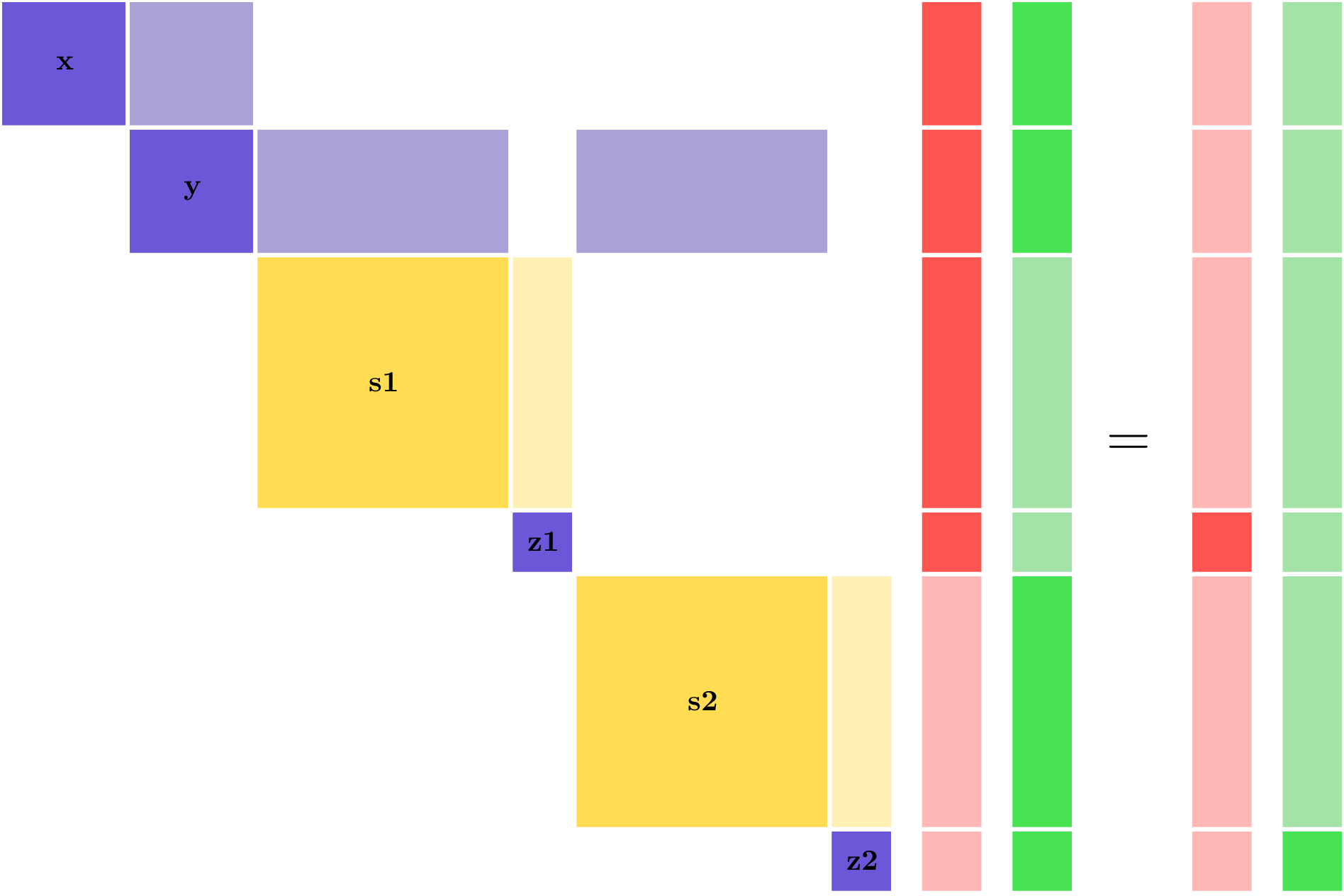
Recall that in the non-linear analysis, moving forward through the model, you could run both the expensive analyses in parallel, and not being able to do the same thing in reverse represents a significant parallel inefficiency.
When solving for derivatives of z1, the z2 components won’t have any work to do and will idle.
Similarly the z1 components won’t have any work to do when solving for derivatives of z2.
That means that in each linear solve half of the computational resources of the model will be idle.
This is represented visually by the light red sections of the vector, representing known zero entries in the vector.
In general, if you had n different z variables, then only \(1/n\) of the total compute resource would be active for any one linear solve.
So despite having good parallel scaling for the nonlinear analysis (moving forward through the model), in reverse mode the parallel scaling is essentially non-existent.
Note
This kind of parallel scaling limitation is unique to reverse mode. If z1 and z2 were very large vectors, and x was smaller vector, then we could use forward mode for the total derivative calculations, and both z1 and z2 would have work to do for every single solve.
Approach for Computing Parallel Derivatives in Multipoint Models#
Keeping in mind that we’ve stipulated that computations for x and y are inexpensive, the existing parallel resources of the model can be leveraged to enable parallel calculation of derivatives for both z1 and z2.
The fundamental problem is that both z1 and z2 need to back-propagate through y and x in order to compute derivatives, so parallelizing the two solves would result in the two back-propagations interfering with each other.
However, we already have two processors (one for s1,z1 and one for s2,z2), so we can duplicate y and x on each processor and then handle the back-propagation for each of the two linear solves on separate processors.
At the end of that back-propagation, each processor will now have the correct derivative for one of the constraints, and the derivative values need to be all-gathered before they can be used.
This duplication will come with a small additional memory cost, because space for x,y must now be allocated in the linear vectors on all processors.
As long as the s1,z1 and s2,z1 variables are much larger, this additional memory cost is negligible.
When using this parallelization algorithm, there are still \(n\) linear solves, for \(n\) variables, but now all of them can be run in parallel to gain back the scaling that is inherently present in the forward mode for this model structure. The linear solves now look like this:
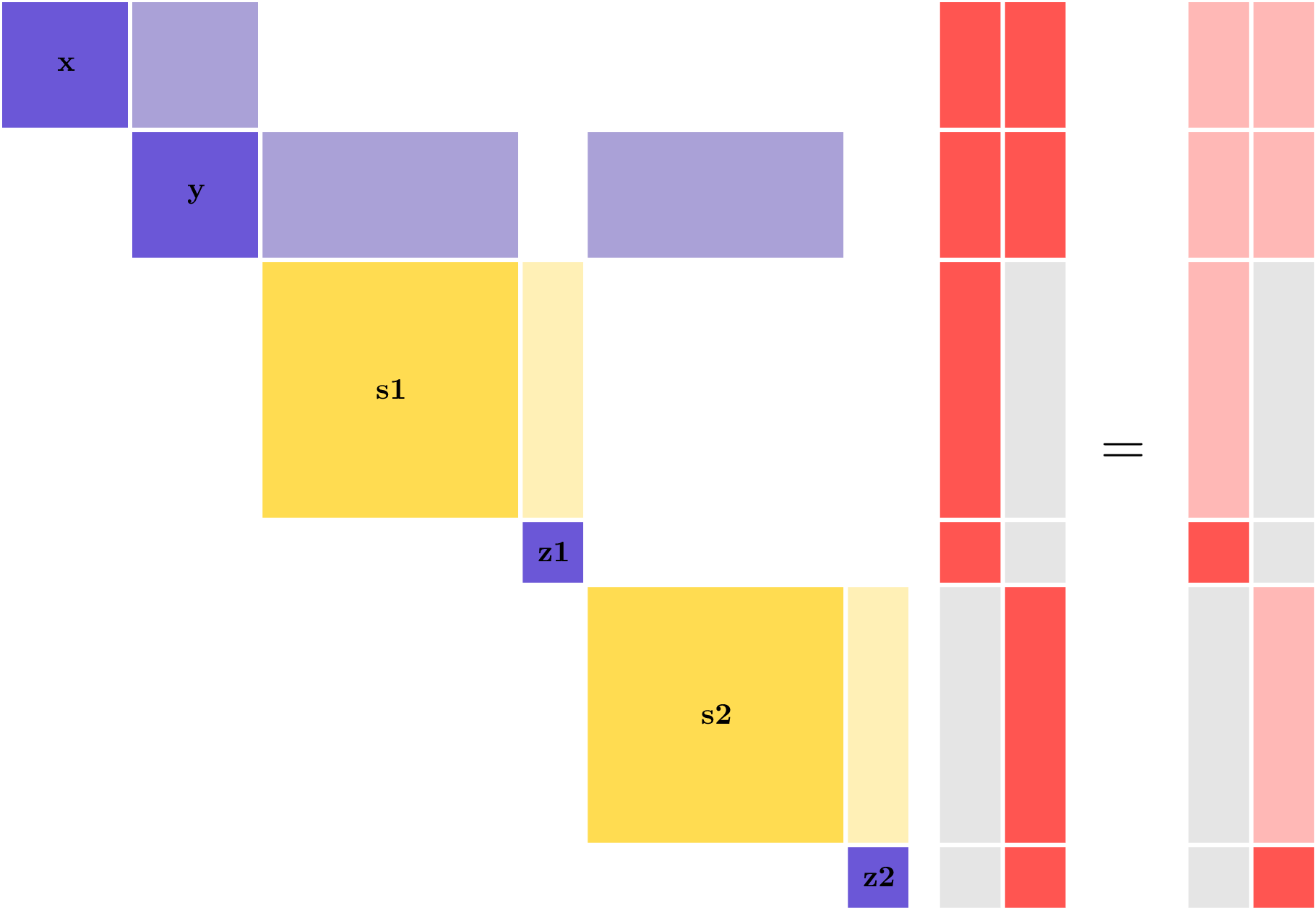
Here, each of the two vectors is being solved for on a different processor. The grayed-out blocks represent memory that is not allocated on that processor.
Coloring Variables for Parallel Derivatives#
In the above example, there was only a single set of variables computed in parallel. Even if the model was larger and ran with \(n\) points across \(n\) processors, all the \(z\) variables could be combined into a single parallel derivative solve. In a parallel coloring sense, all the \(z\) variables belong to the same color.
Consider a slightly more complex problem where each point outputs two different variables: \(a\) and \(b\). Using standard reverse mode, for \(n\) points there would need to be \(2n\) linear solves to compute all the derivatives. Just like before, parallel derivatives are needed to maintain the parallel scaling of the model in reverse mode. However, unlike the earlier problem, there would now need to be two different colors: one for all the \(a\) variables and one for all the \(b\) variables.
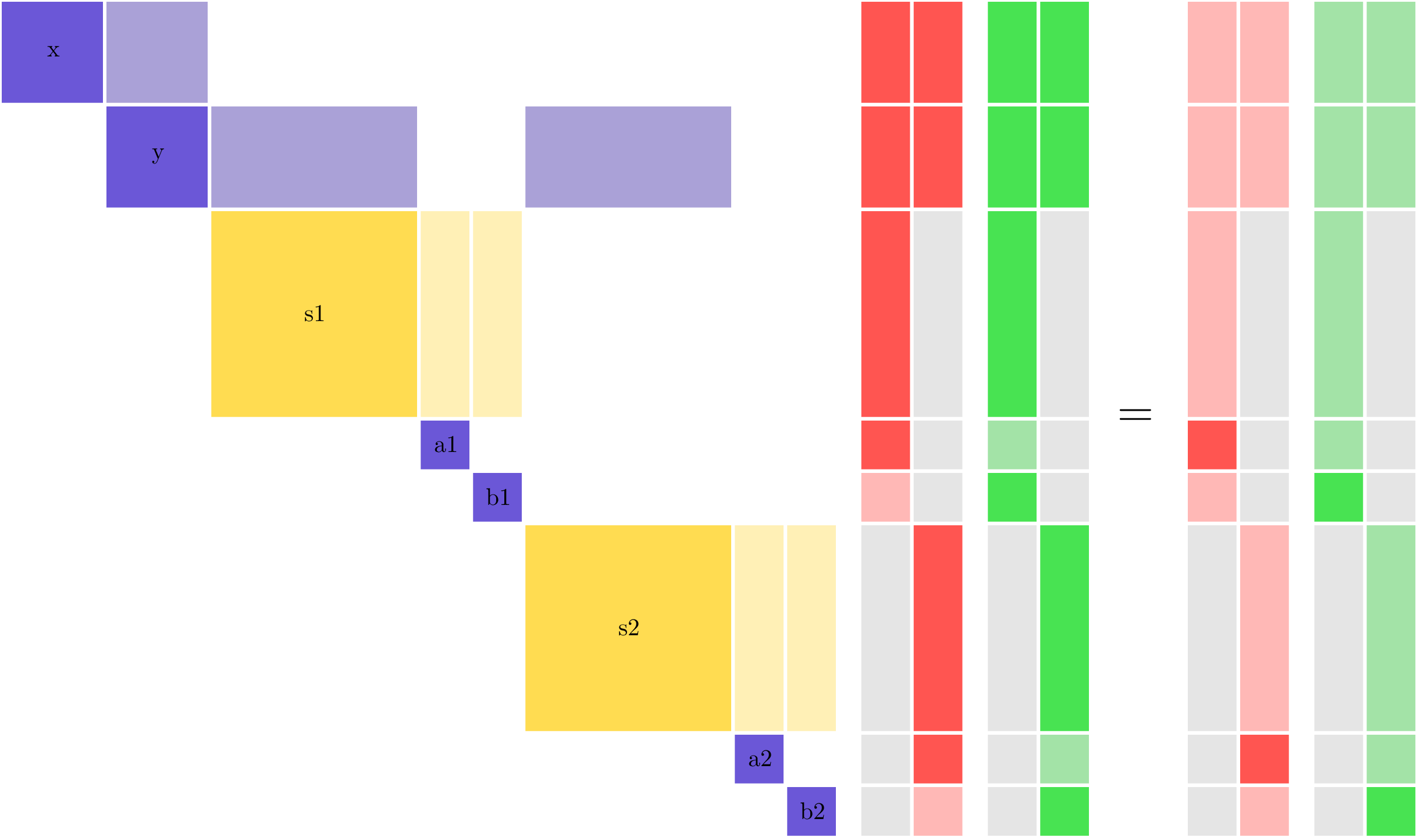
Note
Parallel derivative coloring is distinct from simultaneous derivative coloring. In the parallel coloring, you are specifying variables for which distinct linear solves can be performed in parallel on different processors. In simultaneous coloring you are specifying sets of variables that can be combined into a single linear solve.