How Total Derivatives are Computed#
This is a comprehensive document that explains the various techniques that can be used to compute total derivatives, along with each technique’s strengths and weaknesses. The goal of this document is to help you understand how the underlying methods work, and when they are appropriate to apply to your model. It is designed to be read in the order it’s presented, with later sections assuming understanding of earlier ones.
Partial vs. Total Derivatives#
Before diving into how OpenMDAO solves for total derivatives, it is important that we clearly define a pair of key terms.
Partial Derivative: Derivatives of the outputs or residuals of a single component with respect to that component’s inputs.
Total Derivative: Derivative of an objective or constraint with respect to design variables.
If you are numerically approximating the total derivatives, using finite-difference or complex-step, then you do not need to worry about partial derivatives. However, analytic-derivative methods achieve better accuracy and lower computational cost by leveraging partial derivatives to compute total derivatives.
Numerical Approximation for Total Derivatives#
Numerical approximation of total derivatives involves treating the overall model as a single function and approximating its total derivatives by examining the change in outputs as inputs are varied. These methods involve taking successive steps in each design variable and then computing derivatives based on changes to the output value. Generally speaking each design variable must be examined separately, meaning that the computational cost of these approaches scale linearly with the increasing size of the design space. The primary attraction the numerical approach is that it is relatively simple to implement since no knowledge of the internal workings of the model you are trying to differentiate is required.
The most common numerical approach is to use first-order finite differences to compute the approximations:
While this approach is the simplest possible method, it is also the least accurate. The error of the approximation scales linearly with the step size, \(\Delta x\), which encourages the use of very small values for the step size. However, for very small \(\Delta x\), two challenges arise. First, subtractive cancellation, a problem with floating point arithmetic in computers, fundamentally limits the accuracy of the method for very small steps. Second, if the model includes nonlinear solvers, then noise in the nonlinear convergence for very small steps also introduces error.
To achieve better accuracy, the complex-step method can be used:
This offers second-order convergence with the size of the step in the complex plane \(h\), but more importantly, avoids the issue with subtractive cancellation so that \(h\) can be chosen to be arbitrarily small, and then essentially-perfect accuracy can be achieved. The improved accuracy does come at the expense of greater computational cost and implementation complexity, however. In most cases, changes are required to the underlying model, including any nonlinear solvers, to handle the complex arithmetic which is roughly 2.5 times more expensive than basic real arithmetic.
Basic Approach for Analytic Total Derivatives
While the numerical approach to computing total derivatives is conceptually simpler, analytic approaches are more accurate and less computationally expensive. The analytic approaches all follow a two-step recipe for computing total derivatives.
Directly compute the partial derivatives for each component.
Solve a linear system to compute the total derivatives.
Partial derivatives are simpler and less costly to compute directly, as compared to total derivatives, because in the context of OpenMDAO they only involve a single component and never require re-converging of the nonlinear analysis. OpenMDAO offers several different ways to compute partial derivatives, but for now we’ll assume that the partials are simply known quantities and focus on how to execute step two of the process above.
Consider a function \(f=F(x,y)\) where \(x\) is a design variable vector of length \(n\) and \(y\) is an implicit variable vector of length \(m\). Any evaluation of \(F\) must include the convergence of the nonlinear system \(R(x,y)=0\). We can expand the total derivative as follows:
\(\partial F/\partial x\) and \(\partial F/\partial y\) are partial-derivative terms, which we have assumed are known quantities. We need a way to compute \(d y/d x\), which represents the change in the converged values of \(y\) for a change in \(x\). There are two methods available to compute this term: direct or adjoint.
Direct Method#
The direct method can be derived by recognizing that is always the case that \(R(x,y)=0\) when the model is converged, and differentiating \(R\) with respect to \(x\):
Then re-arrange the terms to get:
Hence, \(d y/d x\) can be computed by solving the above matrix equation consisting of only partial derivatives. Noting that \(\partial R/\partial x\) and \(dy/dx\) are both matrices of size \(m \times n\), we see that the direct method requires us to solve \(n\) linear systems in order to compute all columns of \(d y/d x\). Noting that \(n\) is the length of the design vector, \(x\), we see that the compute cost of the direct method scales linearly with the number of design variables.
Adjoint Method#
The adjoint approach is derived by first substituting the expression for \(d y/ d x\) back into the original equation for \(d f/d x\).
By grouping \(\partial f/\partial y\) and \(\left[\partial R / \partial y \right]^{-1}\) into a single term we get a \((1 \times m)\) row vector. This row vector, denoted as \(\psi^T\), is called the adjoint vector. As long as \(\psi\) can be computed efficiently, then the total derivative can be computable as:
Through a bit of manipulation, we find that \(\psi\) can be solved for via the linear system
This gives us \(\psi\) for the cost of a single linear solve. For a problem with more than one output, you would perform one linear solve and compute one adjoint vector for each output. For example, if you have one objective and two constraints, then you would perform three linear solves to compute all the total derivatives you needed.
The compute cost of the adjoint method scales linearly with the number objectives and constraints you have, but is independent of the number of design variables in your problem.
Unified Derivatives Equations#
The analytic equations (direct or adjoint) above can be combined with the chain rule to compute total derivatives for any arbitrary model. This would achieve the goal of computing total derivatives, knowing only partial derivatives. The only problem is that each new model, composed of different combinations of components connected in different ways, would require you to re-derive a new combination of chain-rule and direct or forward solves to get the totals you need.
To simplify this process, OpenMDAO provides functionality that automatically handles all of that work for you, so that you never actually need to assemble linear systems by hand or propagate derivatives with the chain rule. In order to understand how it automates the task for an arbitrary model, read on!
OpenMDAO relies on a generalization of the various analytic methods for computing total derivatives called the MAUD architecture, developed by Hwang and Martins. For a highly-detailed account of how MAUD can be used to compute total derivatives, we refer you to the paper that describes the math and basic algorithms. In this document, we will simply describe the practical application of the central theoretical contribution of MAUD, the Unified Derivative Equations:
Where \(o\) denotes the vector of all the variables within the model (i.e. every output of every component), \(\mathcal{R}\) denotes the vector of residual functions, \(r\) is the vector of residual values, \(\left[\frac{\partial \mathcal{R}}{\partial o}\right]\) is the Jacobian matrix of all the partial derivatives, and \(\left[\frac{do}{dr}\right]\) is the matrix of total derivatives of \(o\) with respect to \(r\).
The left side of the UDE represents the forward (direct) form, which is solved once per design variable to compute one column of \(\left[\frac{do}{dr}\right]\). The right side of this equation represents the reverse (adjoint) form, which requires one solve per objective and constraint to compute one row of \(\left[\frac{do}{dr}\right]\).
It may look a bit odd to take derivatives of output values with respect to residual values, but Hwang and Martins showed that if you adopt a specific mathematical representation for the equations, then \(\left[\frac{do}{dr}\right]\) contains all the total derivatives you actually want. Again we refer you to the paper on the MAUD architecture for the details, but lets work through an illustrative example.
In an OpenMDAO model, each single equation would be represented by components, and the components would be connected as shown in the XDSM diagram below. Discipline 2 is a different color, because it would be implemented using an ImplicitComponent). All of the red boxes would be built using ExplicitComponents).
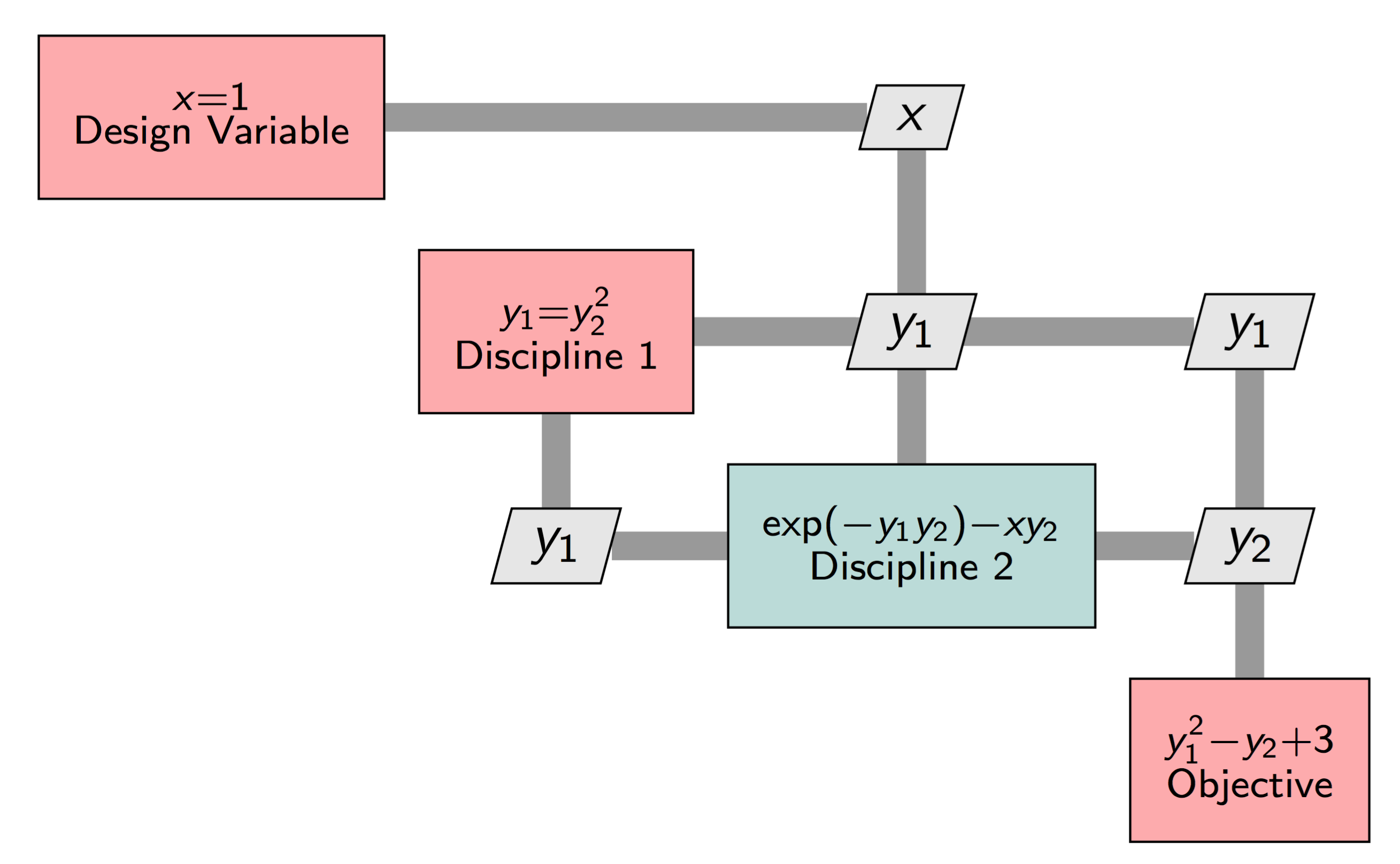
Even though the model is made up of both explicit and implicit calculations, OpenMDAO internally transforms all variables into an implicit form as follows:
Now we can use the fully-implicit form with the UDE to compute \(\left[\frac{do}{dr}\right]\), which would end up being:
Note that the total derivative an optimizer would need, \(\frac{d f}{d x}\), is contained in the last row of \(\left[\frac{do}{dr}\right]\). Since, for this simple one-variable problem, that is the only derivative we actually need, then we don’t need to compute all of \(\left[\frac{do}{dr}\right]\). Rather, we can just compute either the first column or the first row using a single linear solve of the forward and reverse forms of the UDE, respectively. In practice, you would never need to compute all of \(\left[\frac{do}{dr}\right]\), because the variable vector \(o\) contains not just your design variables and objective and constraints, but also all of the intermediate model variables as well. Instead, OpenMDAO will just solve for whichever rows or columns of \(\left[\frac{do}{dr}\right]\) are needed for your particular problem based on the design variables, objectives, and constraints you declared.
Next Steps#
Above, we went over the theory behind how OpenMDAO solves for total derivatives via the Unified Derivative Equations. In the end, it all boils down to performing multiple linear solves to compute rows or columns of the total-derivative Jacobian.
In the next chapters of this theory manual, we will discuss how to structure your model to make sure that the linear solves happen efficiently, and when to apply certain advanced algorithms to dramatically reduce compute cost for derivatives.