OpenMDAO can produce a bunch of very useful report like the N2 diagram, and the scaling report. However, we noticed that a lot of users didn’t know they existed, or did know but didn’t think to generate them during development/debugging. So we’ve decided to automatically make as many reports as we can.
There are a bunch of user controllable settings you can configure to get the exact reports you want, set where they get stored, or turn them off completely.
OpenMDAO is used to design airplanes, so I think the Top Gun reference is appropriate.
OpenMDAO V3.14 is chocked full of speedy goodness. You can check out the full release notes for all the details, but I wanted to highlight two key developments that each give speed in their own special way
Faster Structured Interpolation
The in-house OpenMDAO Applications team had found that some of their Dymos applications were spending excessive amounts of time computing interpolations from data tables from the StructuredMetaModel component. We’ve known for a while that our interpolation code wasn’t super fast. In fact we specifically chose an implementation that we knew to be slower, because it offered N-dimensional capability.
However the bottlenecks in our own work got bad enough that we felt it was time to add some less flexible, but a lot faster option. The new interpolants only work for a fixed dimensionality (i.e. 1D or 3D), but they are about 100x faster. We have a new naming scheme, laid out in POEM 058. Any interpolation method that starts with its dimension (e.g. 3Dlagrange3) is one of the new fast ones. We started off with 1D and 3D interpolants because these were the ones we needed. We plan to add some 2D ones in the future though.
If you are using StrucuturedMetaModel, these new methods are worth a try for sure. If you are using cubic or scipy-cubic then I highly recommend that you give lagrange3 a try, or the 3D-lagrange3 if you are using 3D data. You’ll get a significant speed up either way.
Functional Component API
We’ve introduced a new component API, that can possibly help you code a bit faster. This feature is so big, it spans two whole POEMs: 056 and 057. If you’re going to use the new API, you should definitely read both poems.
Just to be clear, this new API is not going to replace the existing class based one but will live along side it. The new API, as the name suggests lets you build components using standard python functions. It works with both explicit functions and implicit ones
import openmdao.api as om
import openmdao.func_api as omf
def func(a=2.0, b=3.0):
x = 2. * a
y = b - 1.0 / 3.0
return x, y
f = (omf.wrap(func)
.defaults(method='cs')
.declare_partials(of='x', wrt='a')
.declare_partials(of='y', wrt='b'))
p = om.Problem()
p.model.add_subsystem('comp', om.ExplicitFuncComp(f))
p.setup()
p.run_model()
J = p.compute_totals(of=['comp.x', 'comp.y'], wrt=['comp.a', 'comp.b'])
If you don’t like the boiler plate of the class APIs, you may find this API to be a lot cleaner. If you happen to have a library of existing python functions, you’ll probably find this API to be a nice way to integrate that into OpenMDAO without having to write any class wrappers yourself.
The most fundamental motivation for this new API is that it more easily supports algorithmic differentiation (AD). AD relies on functional APIs, and OpenMDAO’s classed based API was always a tough fit. So if you’ve wanted to try out JAX or pyTorch then this new API is for you!
Adding analytic derivatives offers huge computational benefits, but is often a very slow development step. We’ve also found that when taking derivatives by hand, we tend toward smaller components to keep the derivations simpler. Our goal with the functional API is to help alleviate the development bottleneck of derivatives, and offer a path for having larger chunks of engineering code in single components.
October 8, 2021
by Justin Gray Comments Off on Announcing OpenMDAO V3.13
OpenMDAO V3.13.0 is live. You can read the release notes for complete details, but there are a few key changes worth highlighting:
There are some minor improvements to the way OpenMDAO computes relative step sizes. Full details in POEM 051, but in short you can now ask for step sizes for array variables on a per element basis or from an avg array value. The old method has been kept as well for backwards compatibility, though it is deprecated and will be removed in a later version.
POEMS 053 and 054 summarize a change to the way src_indices work. It’s a bit subtle, so I encourage you to read the POEMS. The key take away though is that src_indices behavior now matches what numpy does with array indexing. This is a backwards incompatible change, though you can can check for its impact by using OpenMDAO V3.12 which will give you a clear deprecation warning.
Another small tidibit: We’re starting to work on on speeding up the interpolation routines. We’re not done yet, but we have some early progress. Check out the akima1d and trilinear interpolation methods if you’re looking for speedier table lookups.
July 16, 2021
by Justin Gray Comments Off on V3.10 – OpenMDAO on Google Collab!
We revamped our docs based on jupyter notebooks, so you can run all our docs code on Google Collab. Just look for the rocket-ship icon in the upper right corner of a docs page!
V3.10 has a lot of new features, APIs, and some important deprecations. You can get all the details in the release notes, but here are the highlights.
Major redesign of the APIs for distributed components and variables. See POEM_046 for a lot of details. You now specify distributed independently on each variable.
We now use val everywhere (before there was a mix of val and value. The older keyword has been deprecated, which gives you a chance to update before the 4.0 release. See POEM_050.
An error is raised if you run check_partials and the same settings are used for both the approximated derivatives and the check. Note: We found a surprising number of cases where this was happening. The check is useless in this case. So You might get an new error, but you should be glad that you’re finding what is effectively a bug in your code.
You can now use “fancy” indices (i.e. multi-dimensional slices) for constraints
There is a new flag called under_finite_difference in components to tell you when you’re being finite-differenced (mirrors the existing under_complex_step flag)
New Logo
Have you noticed out new logo? Feel free to stamp it on any thing you like!
June 21, 2021
by Justin Gray Comments Off on value -> val
OpenMDAO V3 is a little inconsistent with it use of val and value as keyword arguments to different API methods. We are going to fix this in V4 by standardizing on val for everything. This change is proposed in POEM 050.
Unfortunately, that is going to cause some “minor” backwards incompatibility for any user code that specifically called out the value keyword. So in V3.11 and higher, we’ll keep backwards compatibility with the old keyword and give you a deprecation warning. This should provide a smooth upgrade path, since you can try out the new code and work to remove the deprecations.
We recognize that these kind of API changes are modestly annoying, but we feel they are a net positive in the long run because don’t have to guess which keyword to use where. If you don’t agree with us, or have an alternate proposal then feel free to chime in with comments or PRs on POEM 050.
May 11, 2021
by Justin Gray Comments Off on Have a look at POEMs 48 and 49
Introducing two new proposals for OpenMDAO enhancement (POEMs), for your consideration. Both are fairly low impact, though POEM 049 does propose removal of some unused APIs.
OpenMDAO Already has both structured and unstructured metamodel components. You might think that those two are the all you would ever need, but there is a semi-structured data format that is fairly common (at least in the aircraft design world). This kind of data is useful for things like performance tables where you can’t necessarily get valid data on a full structured grid. The data looks like this:
x = 1
y = 1, 2, 3, 4, 5, 10, 11
z = 10, 20, 30, 40, 50, 100, 110
x = 2
y = 1, 2, 3, 4, 5, 10, 11
Z = 60, 80, 100, 200, 220
x = 3
y = 1, 2, 3, 4, 5, 10, 11
z = 300, 330, 120, 150, 300, 330
The independent values are always monotonic, but the dependent data does not necessarily have to be. Despite being non-structured, the monotonic inputs allow for the same kind of recursive interpolation that OpenMDAO’s MetaModelStructuredComp uses.
While this POEM does propose a backwards incompatible change, to the best of our knowledge no one is actually using these APIs. If you are using them and want to object to their removal, now is your chance! Please comment on the POEM PR and provide us an example use case where you really need to have it.
These APIs date back to early OpenMDAO V1 days when performance for serial components that provided a dense partial derivative Jacobian were very poor due to some slower internal data formats and the lack of a DirectSolver. At that time, our solution involved augmenting the matrix-vector product APIs with a matrix-matrix product API that would skip a particularly slow OpenMDAO for-loop. It worked to an extend, but was not a very general solution.
Today we have both sparse and dense assembled Jacobians that provide better overall performance in a wider range of use cases. We believe these older matrix-matrix features are not needed, and removing them will simplify several places in the code and make our linear solvers more easily understandable.
If you think otherwise, please speak up. We’d appreciate you providing a use case that shows how the matrix-matrix APIs are significantly faster than using the an Assembled Jacobian and LinearRunOnce or DirectSolver.
Version 3.9’s biggest change is the new serial/distributed api for variables. We now allow you to label individual variables as serial or distributed, which ultimately clears up a lot of confusion when working with distributed memory computations. All of the details are covered in POEM 046. There are lots of other changes in this release, including performance improvements and a few other new features. You can read the release notes for a full accounting, but here are the highlights.
ExecComp Improvements
A small but useful update was made to ExecComp. You can now call the add_expr method on that Component to create new outputs. This change makes the ExecComp API look more similar to the BalanceComp and EQConstraintComps. It also makes for slightly cleaner inputs when you’re using a lot of expressions in your model.
Quieter Warnings
Were you annoyed by the warnings about missing MPI4py or petsc4py? You were not alone! We’ve specifically quieted those two, and you’ll only see them if you try to use those features without the proper packages in stalled. More generally though, we reworked our whole warnings system.
OpenMDAO gives you a lot of freedom, and sometimes that lets you get into trouble. We’ve tried hard to add clear error/warning messages to cover these situations. However, the net result is that sometimes your runs can get kind of noisy. So we re-built our warning system to be more organized, and gave users the ability to limit which ones actually get reported. Check out the docs for the new warning system.
Try to remember, with great power comes great responsibility 🙂 When you suppress warnings you might be missing helpful information. We recommend you leave most warnings on during development and turn them off only for production runs.
April 14, 2021
by Justin Gray Comments Off on V3.8.0 and an upcoming 100x speedup!
OpenMDAO V3.8.0 is out. This is a modest release, but does have some new features. Check out all the release notes for complete details, but here are some highlights:
Ability to save/load views of an N2, so you can keep that specific view you spent a few minutes setting up 🙂
added some preliminary support for ipython notebooks to some of the visualization and variable listing methods.
Bug fixes for exec-comp has_diag_partials argument
Bug fix for the residual based filtering of list_outputs
Bug fix for Nan values breaking the N2
If you do any work with OpenMDAO distributed components, you should check out POEM_046. Ongoing collaborative work between University of Michigan, NASA Glenn, NASA Langley, and Georgia Tech exposed some weaknesses in the current (i.e. as of V3.8.0) apis. So we did a very deep dive to figure out the “right” way. POEM_046 is currently just a proposal, but it should be accepted and implemented in time for V3.10.0 in late May or early June 2021. We put a lot of detail into this POEM, so it could serve as a reference for anyone who wants to understand how OpenMDAO does its stuff. The final APIs are pretty simple, but the majority of the POEM deals with why we decided to go this way. Feedback is more than welcome from anyone!
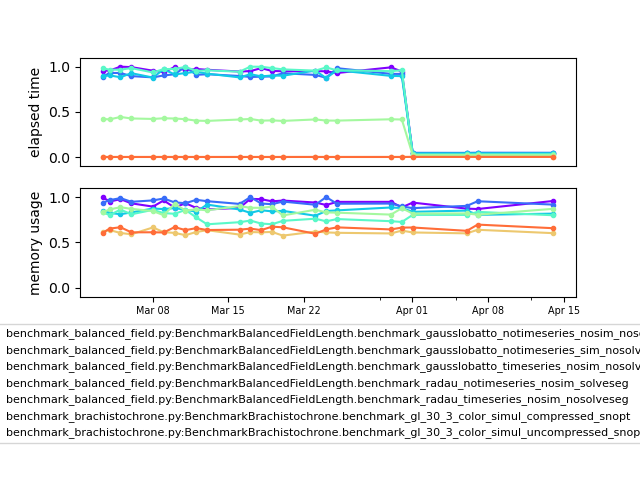
So what about this 99% speedup? Sounds pretty great right? A few weeks ago we noticed this in one of our internal benchmarks:
On April 1st something pretty spiffy happened there right? Please excuse the obtuse benchmark test names. We have a lot of internal benchmarks (we run nightly tests on OpenMDAO core, pyCycle, and Dymos) and we use rather verbose names for them to help make it easy to figure out whats going on. In this case, the benchmarks were from Dymos, and (as the long names suggest) they delt with partial derivative coloring algorithms.
We recently completed a major overhaul of the internal FD/CS partial derivative approximations and the associated partial derivative coloring. Things are now fully sparse internally and work on a column by column basis that is a lot more memory efficient. That massive drop in benchmark times came from this upgrade. If you haven’t tried out the partial derivative coloring, you should give it a look. That goes triple if you’re a dymos user. It lets you use complex-step derivatives and still get a lot of the benefits of sparse partials!
These benchmarks literally got 99% faster, or 100x speedup. Props go to Bret Naylor on the dev team for doing the hard implementation work and to Sandy Mader — the user who suggested the improvement. Bret is pretty humble about the speed up though. He says that the secret was to make the initial code as slow as possible, so there was lots of room for improvement. The new, faster coloring will be released with Version 3.9.0.
February 11, 2021
by Justin Gray Comments Off on OpenMDAO V3.7.0
debugging methods give nicely formatted output in Jupyter notebooks
ExecComp now shows the equations in the info panel for the N2
Bug fixes for parallel solvers
User Defined ExecComp Functions
You can now add register own functions to be used in ExecComp. They can be complex-stepped for derivatives just like normal (or you can mark them as requiring finite-difference instead of you prefer). One of the nice things this will let you do is quickly compose a component that chains several methods together. You can read our thinking on details in POEM 39. Here are the docs for user function registration. If you try this out and have any feedback, don’t hesitate to let the dev team know!
N2 viewer Improvements
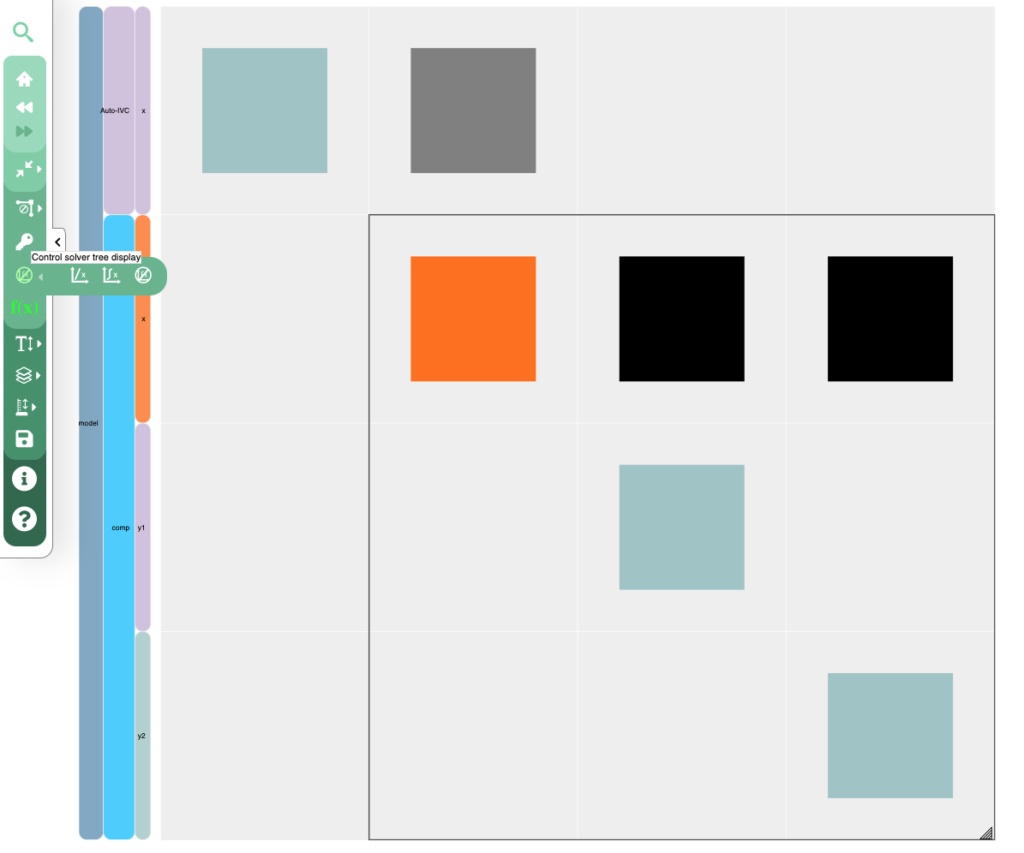
If you haven’t looked closely at the N2 for a while you might have missed a number of small improvements over the last few releases. The info tool can be used on components and variables to see values, units, and other metadata. New in V3.7, if you get the info for an exec-comp, you can see the equations that were used to define it.
The info tool for the N2 viewer give a lot of detail on both components and variables
You can also show/hide the solver hierarchy and highlight the design variables/constraints/objective as well.
Show or hide the solver hierarchy, and highlight the driver variables
January 17, 2021
by Justin Gray Comments Off on New Release: OpenMDAO 3.6.0
Version 3.6.0 marks a huge milestone for OpenMDAO. This is the second release in a row where there are no backwards incompatible API changes! Hurray! To celebrate we released our new logo!
Lest you think we just made a release without changing anything … check out the release notes. Here are the highlights
Scaling Reports
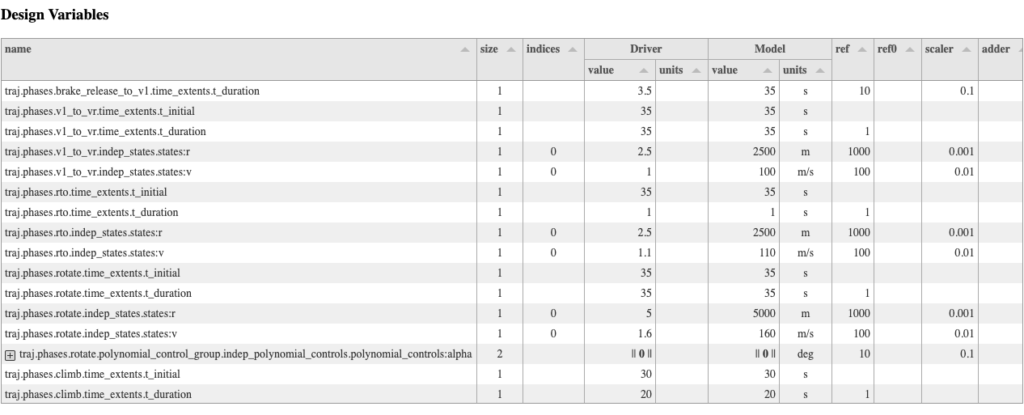
In our internal use cases, particularly with Dymos based problems, we’ve been struggling with optimization scaling. We’re starting to look into some more advanced methods for scaling, but the first step to improving things is understanding what you have in the first place. We built a scaling report tool that helps you get that information in one place. To run it, you can call the OpenMDAO command line openmdao scaling <your run script
Tables of data give details on the scaling for your design variables, and constraintsA visualization of the total derivative Jacobian lets you see the sparsity pattern, and the magnitude of the various sub-Jacobians in your model.
N2 Improvements
Include data about which surrogate is used in metamodels
Can now hide the solver hierarchy in the N2 (useful if you want to make slightly lower-aspect ratio movies of the N2)
Included a button to show/hide the design variables, objective, and constraints