OpenMDAO V3.8.0 is out. This is a modest release, but does have some new features. Check out all the release notes for complete details, but here are some highlights:
- Overhaul of the internal storage vectors (relevant if you’re doing cool stuff inside the guts of OpenMDAO like these folks from DLR)
- Ability to save/load views of an N2, so you can keep that specific view you spent a few minutes setting up 🙂
- added some preliminary support for ipython notebooks to some of the visualization and variable listing methods.
- Bug fixes for exec-comp
has_diag_partialsargument - Bug fix for the residual based filtering of
list_outputs - Bug fix for
Nanvalues breaking the N2
If you do any work with OpenMDAO distributed components, you should check out POEM_046. Ongoing collaborative work between University of Michigan, NASA Glenn, NASA Langley, and Georgia Tech exposed some weaknesses in the current (i.e. as of V3.8.0) apis. So we did a very deep dive to figure out the “right” way. POEM_046 is currently just a proposal, but it should be accepted and implemented in time for V3.10.0 in late May or early June 2021. We put a lot of detail into this POEM, so it could serve as a reference for anyone who wants to understand how OpenMDAO does its stuff. The final APIs are pretty simple, but the majority of the POEM deals with why we decided to go this way. Feedback is more than welcome from anyone!
So what about this 99% speedup? Sounds pretty great right? A few weeks ago we noticed this in one of our internal benchmarks:
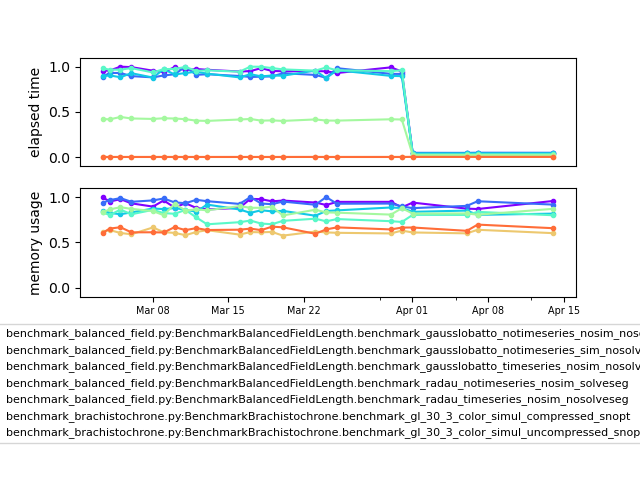
On April 1st something pretty spiffy happened there right? Please excuse the obtuse benchmark test names. We have a lot of internal benchmarks (we run nightly tests on OpenMDAO core, pyCycle, and Dymos) and we use rather verbose names for them to help make it easy to figure out whats going on. In this case, the benchmarks were from Dymos, and (as the long names suggest) they delt with partial derivative coloring algorithms.
We recently completed a major overhaul of the internal FD/CS partial derivative approximations and the associated partial derivative coloring. Things are now fully sparse internally and work on a column by column basis that is a lot more memory efficient. That massive drop in benchmark times came from this upgrade. If you haven’t tried out the partial derivative coloring, you should give it a look. That goes triple if you’re a dymos user. It lets you use complex-step derivatives and still get a lot of the benefits of sparse partials!
These benchmarks literally got 99% faster, or 100x speedup. Props go to Bret Naylor on the dev team for doing the hard implementation work and to Sandy Mader — the user who suggested the improvement. Bret is pretty humble about the speed up though. He says that the secret was to make the initial code as slow as possible, so there was lots of room for improvement.
The new, faster coloring will be released with Version 3.9.0.
